כמו כל דף אינטרנט, גם מבנה ה XHTML של פרק בספר הדיגיטלי – מורכב מתתי רכיבים בעץ מבנה מסודר תחת BODY אחד. פסקאות, תמונות וטבלאות הן רק חלק מרכיבים אפשריים אלה. לרוב, בספר טקסטואלי, יכיל כל פרק רצף פסקאות רב בחלוקה למשפטים או לקטעי הטקסט בהתאם לעיצוב. אבל למה זה מעניין אותנו? מה זה משנה אם נחלק את הטקסט לפסקאות בגדלים סבירים או אולי בכלל כדאי שנפצל את הטקסט לרכיבי SPAN לכל מילה בנפרד? (כמו בדוגמה 2 כאן בפוסט – שנלקחה מספר מוכר המופץ בחנויות בישראל)
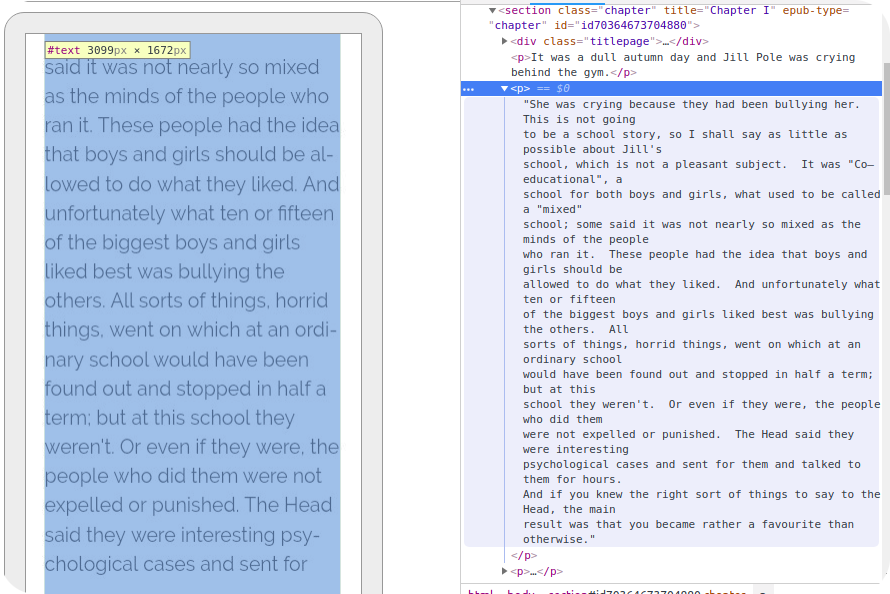
פסקה עצומה המתארכת על פני פספר עמודים
קטן מדי זה לא טוב
זו לא כותרת מרומן אירוטי מוכר, אלא התייחסות לגודל הרכיבים שבהם מעוצב הטקסט. אמנם אנו יכולים לפצל חלקי פסקאות, או אפילו מילים, לתתי רכיבים באמצעות SPAN והעיצוב שלנו לרוב לא יושפע מכך, אך עיצוב כזה הוא שגוי מיסודו. לא רק שאפליקציית הקריאה צריכה לסרוק, להמיר ולבנות את כל חלקי ה"פאזל" מחדש לשם קריאה תקינה, גם גודל הספר יכול לגדול באופן משמעותי, כאשר תגיות ה-SPAN תופסות יותר מקום מאשר הטקסט עצמו.
דוגמה 2
עומס נורא בחלוקה למילים ואפילו מרווחים במילים - שנוצר על ידי תוכנת אין-דיזיין
מיקום אחרון וסימניות
בעיה חשובה מאוד הנגרמת כפיצול לא סביר לפיסקאות גדולות מדי נובעת מתקן CFI לסימון מקום קריאה בספר, כגון סימניות או טקסט מודגש. תקן CFI מתבסס על מבנה עץ הרכיבים בקובץ, כאשר מיקום בפרק נקבע על פי מיקום הרכיב המסויים שאנו מציגים באותו רגע. פסקה ארוכה אחת נחשבת כרכיב אחד. ולכן סימון סימניה "על גבי" פסקה ארוכה הנמרחת על פני מספר עמודים – תחזיר אותנו לתחילת אותה פיסקה ולא לאותו עמוד בו סימנו את אותה סימניה.